



Text analysis is a series of machine learning, statistical and linguistic techniques to process large volumes of unstructured text or text without a predefined format to derive insights and patterns. It allows businesses, governments, researchers, and the media to make important decisions with the vast amount of content at their disposal. Text analytics uses a variety of techniques such as sentiment analysis, topic modeling, named entity recognition, term frequency, and event extraction. Choose the best platform that offers Text analytics, there are many other platforms that offer text analytics capabilities.
What is the difference between text mining and text analysis?
Text mining and text analysis are often used interchangeably. The term text mining is commonly used to derive qualitative insights from unstructured text, whereas text analysis provides quantitative results.
For example, text mining can be used to analyze customer reviews and surveys to identify satisfaction with a product. Text analytics is used for deeper insights, such as identifying patterns or trends in unstructured text. For example, text analytics can be used to understand negative spikes in customer experience or product popularity.
Then, the text analysis results in data visualization technology can be used with, to make it easier to understand and make faster decisions.
What is the relevance of text analysis in today’s world?
As of 2020, approximately 4.57 billion people will access the Internet. This equates to about 59% of the world’s population. About 49% of them are active on social media. Huge amounts of text data are generated every day in the form of blogs, tweets, reviews, forum discussions, and surveys. Besides, most customer interactions are now digitized, creating another huge text database.
Most text data is unstructured and spread across the web. Properly collecting, sorting, structuring, and analyzing this textual data can provide valuable knowledge. Organizations can use these insights to take action to improve profitability, customer satisfaction, research, and national security.
Benefits of text analytics
There are many ways text analytics can help businesses, organizations, and event social movements.
- Help businesses understand customer trends, product performance and service quality. As a result, rapid decision-making, and business intelligence Improve productivity, increase productivity and reduce costs.
- It helps researchers to extract research-related content by exploring large amounts of existing literature in a short amount of time. This helps with faster scientific results.
- It helps governments and political institutions understand general trends and opinions in society so that they can make decisions.
- Text analytics technology helps improve the performance of search engines and information retrieval systems to provide a fast user experience.
- We improve our user content recommendation system by categorizing relevant content.
Text analytics techniques and use cases
There are several techniques involved in analyzing unstructured text. Each of these technologies is used for different use case scenarios.
Sentiment Analysis
Sentiment analysis is used to identify the emotions conveyed by unstructured text. Input text includes product reviews, customer interactions, social media posts, forum discussions, or blogs. There are different types of sentiment analysis. Polarity analysis is used to identify whether a text expresses positive or negative emotions. Classification techniques are used for more granular analysis of emotions such as confusion, disappointment, or anger.
Use cases for sentiment analysis:
- Measuring customer response to a product or service
- Understand audience trends for your brand
- Understanding new trends in the consumer space
- Prioritize customer service issues based on severity
- Track how customer sentiment evolves over time
Topic modeling
This technique is used to find key topics or topics in vast sets of texts or documents. Topic modeling identifies keywords used in text to identify the topic of an article.
Use cases for topic modeling:
- Large law firms use subject modeling to examine hundreds of documents during large litigation.
- Online media uses topic modeling to select popular topics on the web.
- Researchers use subject modeling for exploratory literature reviews.
- Businesses can decide which products are successful.
- Topic modeling helps anthropologists identify emerging issues and trends in society based on the content people share on the web.
Named Entity Recognition (NER)
NER is a text analysis technique used to identify named entities such as people, places, organizations, and events in unstructured text. NER extracts nouns from text and determines the values of these nouns.
Use Cases for Named Entity Recognition:
- NER is used to classify news content based on the people, places, and organizations that appear in the news content.
- Search and recommendation engines use NER for information retrieval.
- For large chain companies, NER is used to categorize customer service requests and assign them to specific cities or stores.
- Hospitals can use NER to automate the analysis of lab reports.
Term Frequency – Inverse Document Frequency
The TF-IDF is used to determine how often a term appears in a large text or group of documents and the importance of that term to a document. This technique uses inverse document frequency coefficients to filter out frequently occurring but not insightful words, articles, propositions, and conjunctions.
Event Extraction
This is an advanced text analysis technique over named entity extraction. Event extraction recognizes mentioned events in textual content, such as mergers, acquisitions, political movements, or important meetings. Event extraction requires an advanced understanding of the meaning of textual content. Advanced algorithms try to recognize the event as well as the place, participant, date and time, if applicable. Event extraction is a beneficial technique with multiple uses in many fields.
Event extraction use cases:
- Link Analysis: A technique to understand “who met whom and when” by extracting events from communications via social media. It is used by law enforcement agencies to predict possible threats to national security.
- Geospatial analysis: Once events are extracted along with their locations, insights can be used to map them. This is useful for geospatial analysis of events.
- Business Risk Monitoring: Large organizations deal with multiple partner companies and suppliers. Event extraction technology allows businesses to monitor the web to see if partners, such as suppliers or traders, are dealing with adverse events such as lawsuits or bankruptcy.
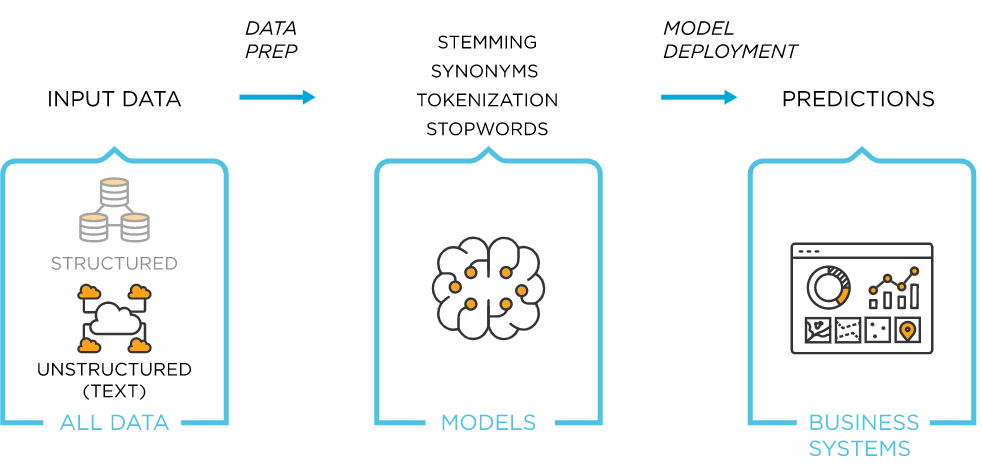
Steps involved in text analysis
Text analysis is a sophisticated technique that involves several pre-steps for collecting and organizing unstructured text. There are many ways in which text analysis can be performed. This is an example of a model workflow.
- Data Collection – Text data is often scattered across an organization’s internal databases, including customer chats, emails, product reviews, service tickets, and pure customer referral index surveys. Users also generate external data in the form of blog posts, news, reviews, social media posts, and web forum discussions. Internal data is readily available for analysis, but external data must be collected.
- Data preparation – When unstructured text data becomes available, it must go through several preparatory steps before it can be analyzed by machine learning algorithms. In most text analysis software, this step happens automatically. Text preparation involves several techniques that use natural language processing, such as:
- Tokenization: In this step, a text analysis algorithm breaks a continuous string of text data into tokens or smaller units that make up whole words or phrases. For example, character tokens can be individual characters of the word FISH, or they can be broken down into subword tokens, like Fish-ing. Tokens represent the foundation of all natural language processing. This step also deletes all unwanted content of the text, including spaces.
- Part-of-speech tagging: In this step, each token in the data is assigned a grammatical category such as nouns, verbs, adjectives, and adverbs.
- Parsing: Parsing is the process of understanding the syntactic structure of text. Dependency parsing and component parsing are two popular techniques used to derive syntactic structures.
- Headword extraction and stemming: These are two processes used in data preparation to remove suffixes and suffixes associated with tokens and to preserve dictionary form or lemma.
- Stopword Removal: This is the stage where all tokens that occur frequently but have no value in text analysis occur. This includes words like ‘and’, ‘the’, and ‘a’.
- Text Analysis – After preparing your unstructured text data, you can now perform text analysis techniques to gain insight. There are several techniques used in text analysis. Among them, text classification and text extraction stand out.Text classification: This technique is also known as text classification or tagging. In this step, specific tags are assigned to the text according to its meaning. For example, tags like “positive” or “negative” are assigned while analyzing customer reviews. Text classification is often done using rule-based systems or machine learning-based systems. In a rule-based system, humans define associations between language patterns and tags. “Good” can indicate a positive evaluation. “Bad” can identify negative reviews.Machine learning systems use past examples or training data to assign tags to new data sets. The training data and its volume are very important because larger data sets help machine learning algorithms to provide accurate tagging results. The main algorithms used for text classification are SVM (Support Vector Machine), NB (Naive Bayes Family of Algorithms), and Deep Learning Algorithms.Text extraction: The process of extracting recognizable and structured information from unstructured input text. This information includes keywords, person names, places, and events. One simple way to extract text is a regular expression. However, this is a complex method to maintain as the complexity of the input data increases. Conditional Random Field (CRF) is a statistical method used for text extraction. CRF is a sophisticated but effective way to extract important information from unstructured text.
What happens after text analysis?
When text analysis methods are used to process unstructured data, output information can be provided to data visualization systems. The results can then be visualized in the form of charts, diagrams, tables, infographics, or dashboards. This visual data enables businesses to quickly spot trends in data and make decisions.


